DeepSeekMoE 与 MTP — V3 留下的两件遗产
DeepSeekMoE 与 Multi-Token Prediction 仍是 V4 的脊梁;但 MoE 的细节被改了五处,每一处都对应一个具体的"V3 时代撞过的墙"。
DeepSeekMoE + MTP = V3 留给 V4 的两根脊梁
FFN 层的稀疏激活骨架 + 训练信号致密化的辅助头。两者在 V3 上验证过,V4 完全保留主体,只在 MoE 的5 个细节上动刀以适配新规模(384 专家 / 1M 序列)。
- MoE(Mixture-of-Experts,专家混合)
- 把单个 dense FFN 拆成 $N$ 个并行专家,每个 token 由路由器 (router) 打分选 top-$k$ 个专家激活。总参数大、激活参数小 —— 模型容量上去但单步算力没涨。
- DeepSeekMoE(Dai 2024)
- DeepSeek V2/V3 时代定下的 MoE 三件套:① 细粒度专家(256 个小专家替代 8 个大专家)+ ② 共享专家(1 个 always-active 专家承通用能力)+ ③ aux-loss-free 负载均衡(不靠 loss 项,靠每个专家的动态偏置 $b_i$ 调节)。
- aux-loss-free 负载均衡
- 传统 MoE 在 loss 里加一项"惩罚不均衡",会和主任务竞争。V3 改成给每个专家维护一个偏置 $b_i$,根据"被分配到的 token 数 vs 期望"在线调整 —— 不动主 loss、闭环平衡专家。
- MTP(Multi-Token Prediction,多 token 预测)
- 主模型旁挂一个轻量 head,让它同时预测未来第 2、3、… 个token(不止下一个)。同一份 hidden state 给多份梯度,训练信号密度 ×D,且强迫 hidden state 编码更长程语义。V3 验证有效,V4 完全沿用,只调权重 schedule。
- Hash Routing(Roller 2021)
- 不学习路由,按 token id 的 hash mod 专家数直接派单。用在前 3 层 MoE,避开"早期 router 没学好就抖"的问题,又享受 MoE 稀疏激活红利。
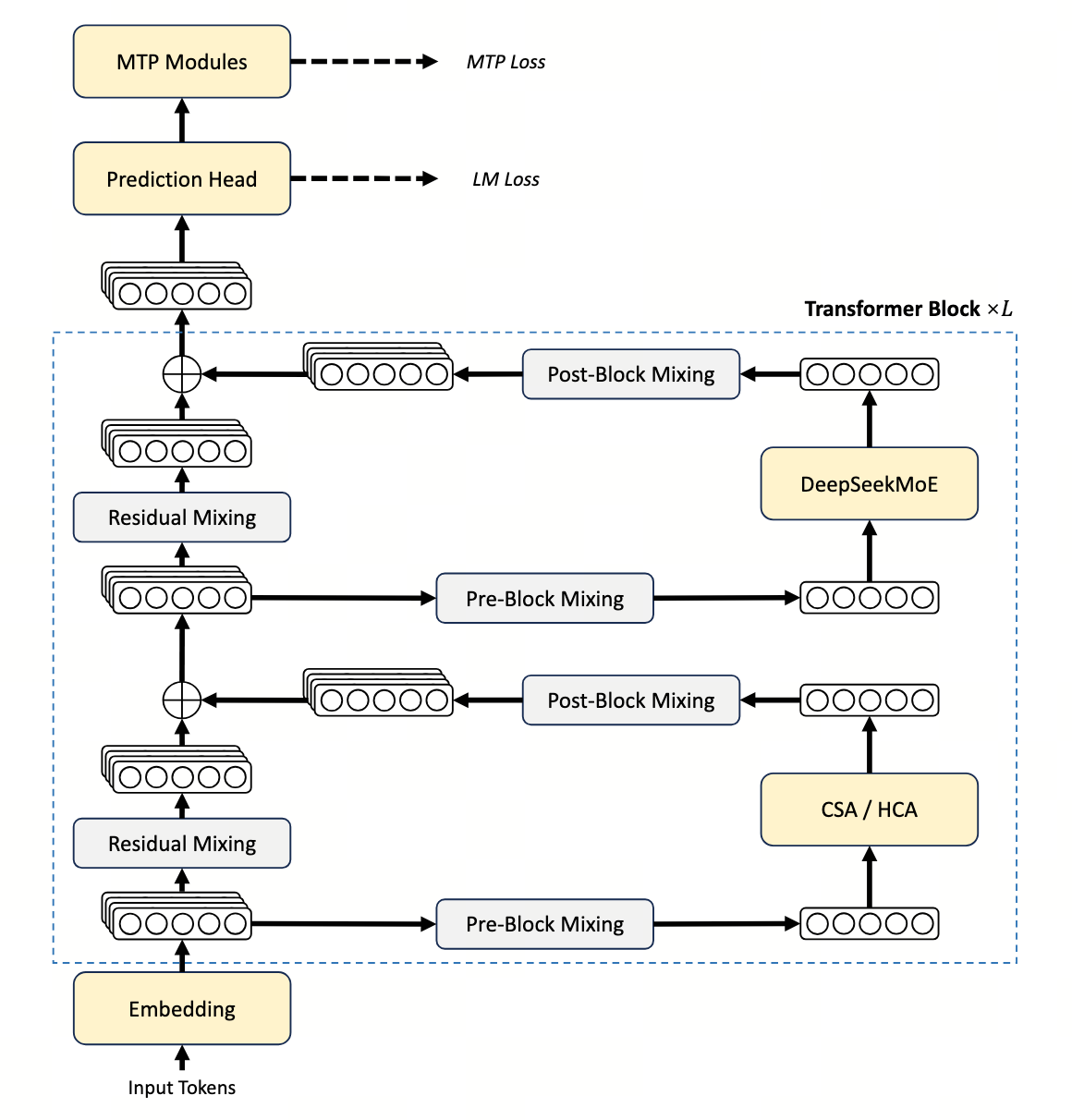
1. 先看 V3 的 DeepSeekMoE 干了什么
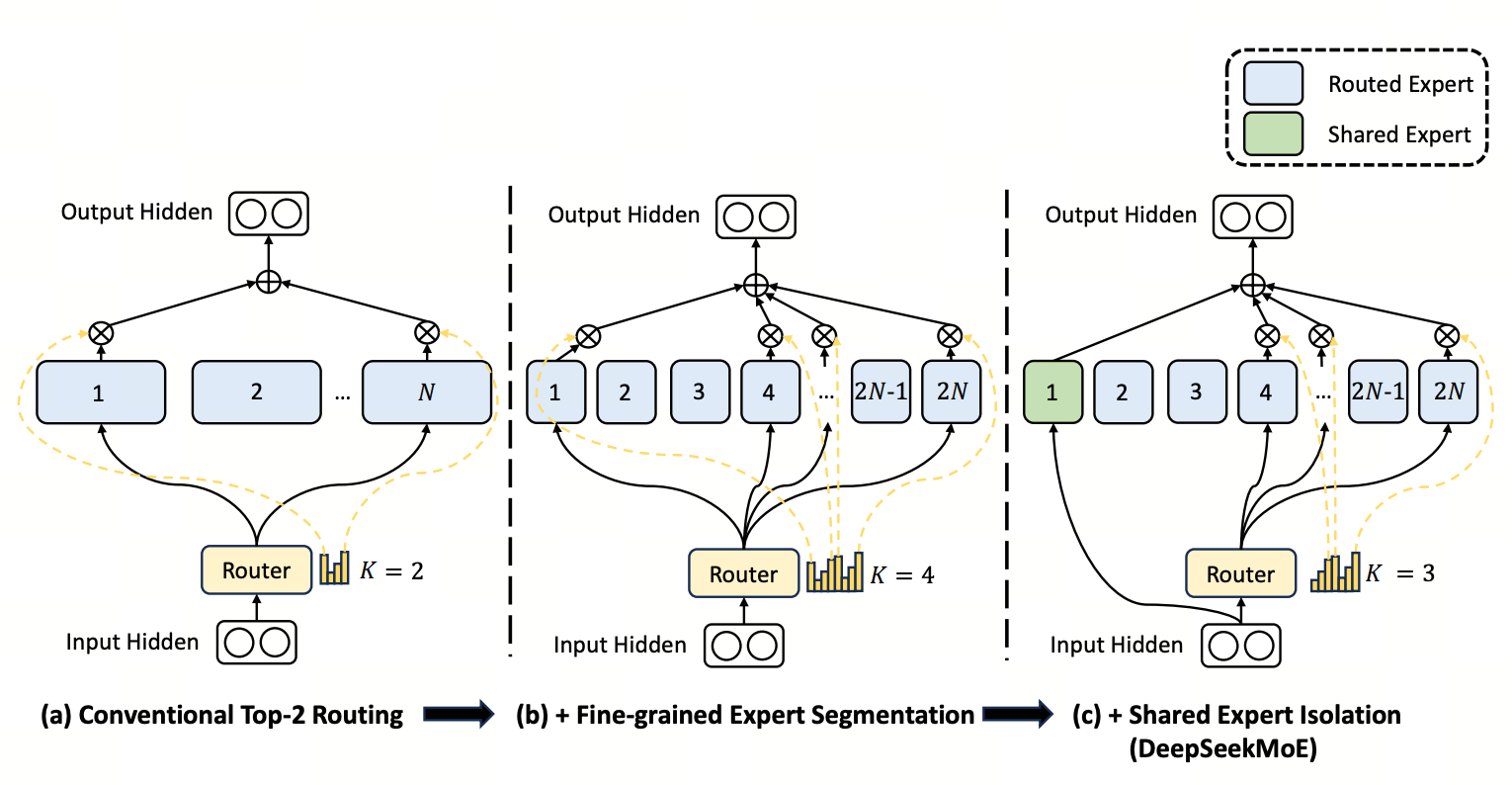
MoE 的标准做法:FFN 层不再是单一稠密网络,而是 $N$ 个并行专家 $\{E_1, \ldots, E_N\}$。每个 token 由路由器打分,选出 top-$k$ 个专家激活。原始 GShard 用 $N=8$、$k=2$,专家间隔很粗。
DeepSeekMoE(V2/V3)做了三个关键改造,这些 V4 完全继承:
- 细粒度专家:把 $N=8$ 个大专家切成 $N \cdot s = 64$ 个小专家(每个尺寸缩到 $1/s$),同时把 $k$ 也乘以 $s$。同样总激活参数下,专家组合数指数级增加。
- 共享专家:另设 1 个 always-active 专家承担"通用知识",让路由专家专注差异化能力。
- aux-loss-free 负载均衡:见上方名词速通。不动主 loss,闭环调控全局负载。
V4 的总专家数从 V3 的 256 涨到 384,激活专家从 8 涨到(Pro)9 / (Flash)8,总参数从 671B 涨到 1.6T。规模一上来,V3 的几个 trick 开始显出毛刺,于是 V4 在 5 个细节上动了刀。
2. 改动 ① 路由打分:Sigmoid → Sqrt(Softplus)
V3 的做法:路由 logits 经过 $\text{Sigmoid}(\cdot)$ 得到打分,再做 top-$k$ 选择和重新归一化。
它哪里不够:
- Sigmoid 上界是 1,logits 大到一定程度就饱和。当模型确信"这个 token 应该去专家 #42"时,logit 可能是 8、12、20 —— 但 Sigmoid 都吐 ≈1,不再有区分度。
- 专家数从 256 → 384,"top-9 专家间的细微优劣"更重要。Sigmoid 在饱和区梯度趋零,路由器学不到"这个专家比那个稍强一点"。
V4 改成:
这条公式是"两层活塞":
- 下层 Softplus:$\log(1+e^{\ell_i})$ —— 把任意 logit 推到 $(0, +\infty)$,没有上界,logit 越大 score 越大,绝不饱和。logit 极小时趋零,自动屏蔽弱专家。
- 上层 sqrt:把 Softplus 的"线性尾巴"压成"平方根尾巴",给一个软上界 —— score 仍单调上升,但增长率随 $\ell$ 越来越慢。
没有上层 sqrt 的话,单个超强专家的分数会把其他专家在归一化后挤到接近 0,等同于"硬选 1 个专家",丢掉了多专家协作。无上界解决饱和、软上界保多专家协作 —— 缺一不可。
把滑条拉到 ℓ=8 看三个读数:Sigmoid≈1.000(已饱和、梯度近零),Softplus≈8.000(无界),√Softplus≈2.83(软上界、仍可区分)。 两个专家的 logits 一个 8 一个 12,Sigmoid 都给 ≈1 看不出谁强;√Softplus 分别给 2.83 和 3.46,仍保留区分度。
3. 改动 ② 序列内 balance loss:补 aux-free 在长序列上的盲区
V3 的 aux-loss-free 是怎么工作的:
$b_i$ 是专家 $i$ 的动态偏置,$\bar{f}_i$ 是过去 $T$ 步内被分给专家 $i$ 的 token 比例,$\bar{f}^* = k/N$ 是均匀目标比例。如果 $i$ 被分得太少,$b_i$ 上调,下一步打分就提升一点 —— 不动主 loss,闭环调控全局负载。
它在 V4 规模上撞墙:$b_i$ 的更新粒度是跨步全局的。但 V4 的训练序列动辄 64K~1M 长,同一条序列内可能强烈偏好某些专家(比如一篇 Python 长文档全程偏向 code 专家)。aux-free 看不到这种"序列内偏置"—— 它只知道"过去 1024 步全局均衡",对单序列内 6× 的不均衡袖手旁观。
V4 加了什么:
这条 loss 是"在单序列尺度对 router 罚一下不均衡":
- $f_i^{(\text{seq})}$ = 这条序列里被分给专家 $i$ 的 token 比例(离散的统计值,不可微);
- $p_i^{(\text{seq})}$ = 这条序列里 router 给专家 $i$ 的平均概率(可微,梯度从这里走);
- 两者相乘求和:如果某个 $i$ 已经分得太多($f_i$ 大),且 router 还在给它高概率($p_i$ 大),loss 就大,反向传播会让 router 降它的 $p_i$。
aux-free 管全局,seq-bal 管局部,两层互补 —— 这是 V4 在长序列时代的必要补丁。$\beta$ 取 $10^{-4}$ 量级,仅作"温和提示",不喧宾夺主。
4. 改动 ③ 取消"路由目标节点上限"
V3 的限制:每个 token 路由的专家最多落在 $M$ 个不同的硬件节点上(V3 取 $M=4$)。这是为了控全节点 all-to-all 通信成本 —— 通信节点越多越贵。
它的代价:当 token 真正"想去"的 top-9 专家分布在 5 个节点时,第 5 个节点的专家被强行替换成"次优 + 同节点"专家。路由质量被通信预算扭曲。
V4 的解法:直接取消上限,让 token 路由到任何专家。代价由 Ch7 的 MegaMoE + DualPipe + 通信压缩承担 —— 基础设施够便宜了,所以模型层不需要再做这种妥协。这就是架构与系统协设:上层不给下层让步,下层兜住成本。
5. 改动 ④ 头几层 Dense FFN → Hash-Routed MoE
V3 的做法:前 1~3 层用 Dense FFN(不做 MoE),后面才开始 MoE。常见的稳定性套路:早期层负责低级特征,路由器还没学好,强行 MoE 容易抖。
它的浪费:Dense FFN 在大模型里参数密度低 —— 早期层用了同样的 GPU 算力,却没享受 MoE 的"激活稀疏 + 总参数高"红利。
V4 改成 Hash Routing(Roller 2021):
路由不学,由 token id 直接哈希到一个专家:
- 不需要梯度训练 router → 没有"早期 router 抖"问题;
- 哈希在统计上均匀 → 天然负载均衡,不需要 aux-free / seq-bal;
- 仍享受 MoE 的稀疏激活红利。
关键洞察:学习型路由的不稳定主要发生在前 1-2 层,因为这些层的 hidden state 还没成型,路由器拿到的特征噪声大。Hash 路由用"反正这层学不了好路由"的事实,干脆放弃学习 —— 是"知道哪里不该学"的典型应用。前 3 层用 Hash MoE,后续层用学习型 MoE。
6. MTP(Multi-Token Prediction):为什么完全不动
MTP 模块的工作机制:在主模型旁边接一个轻量 head $h_{\text{MTP}}$,让它预测未来第 2、3、… 个 token(不止下一个)。损失为:
三件事:
- 预测多个未来 token:$\hat y_{t+j}$ 是从位置 $t$ 出发预测未来第 $j$ 个;
- 逐个算交叉熵:$\mathrm{CE}(\cdot)$ 是常规 LM loss;
- 越远权重越低:$\alpha_j$ 随 $j$ 增大递减,远 token 监督信号弱(毕竟越远越难预测)。
同一份 hidden state 给 $D$ 份梯度,训练信号密度 $\times D$;同时强迫 hidden state 编码"未来一段语义弧线",而不只是"下一个词"。
V4 的 MTP loss 总权重维持 0.3,学习率衰减阶段降到 0.1。降权重的逻辑是:
- 训练前期 hidden state 不稳,MTP 提供致密梯度有助于快速塑形;
- 训练后期主 loss 已经在精修,MTP 的"远 token 监督"开始与主目标产生小幅冲突 —— 降权让主 loss 主导。
因此 V4 完全不改 MTP 模块本身,只调权重 schedule —— 已经被 V3 反复验证、没有失效模式被暴露的组件,就不要动。
7. 五处改动的汇总
| 组件 | V3 行为 | V4 行为 | 对应解决的具体问题 |
|---|---|---|---|
| 路由打分 | Sigmoid | Sqrt(Softplus) | 384 专家间饱和区无区分度 |
| 负载均衡 | 仅 aux-free | aux-free + 序列内 balance loss | 长序列内单序列偏置 aux-free 看不见 |
| 路由节点上限 | $M=4$ | 取消 | 路由质量不再被通信预算扭曲 |
| 前几层 FFN | Dense | Hash-Routed MoE | 避免学习型路由早期不稳,又享受 MoE 红利 |
| MTP 模块 | 权重 0.3 | 权重 0.3,衰减期降 0.1 | 主 loss 后期减少 MTP 干扰 |
V3 的 MoE 主体被完整继承,但 V4 在 5 个细节上"补漏": 打分函数换成不饱和的 Sqrt(Softplus)、加序列内 balance、取消通信驱动的路由限制、把 dense 早层换成 hash MoE、MTP 权重做 schedule。 每一处改动都对应一个 V3 时代被新规模(384 专家、1M 序列)暴露出来的具体毛刺。