mHC — 残差通路的几何护栏
从"残差等于加法"到"残差等于带几何约束的矩阵混合"—— V4 把 60+ 层堆叠的稳定性问题搬到了流形上。
mHC = Manifold-constrained Hyper-Connection(流形约束的超连接)
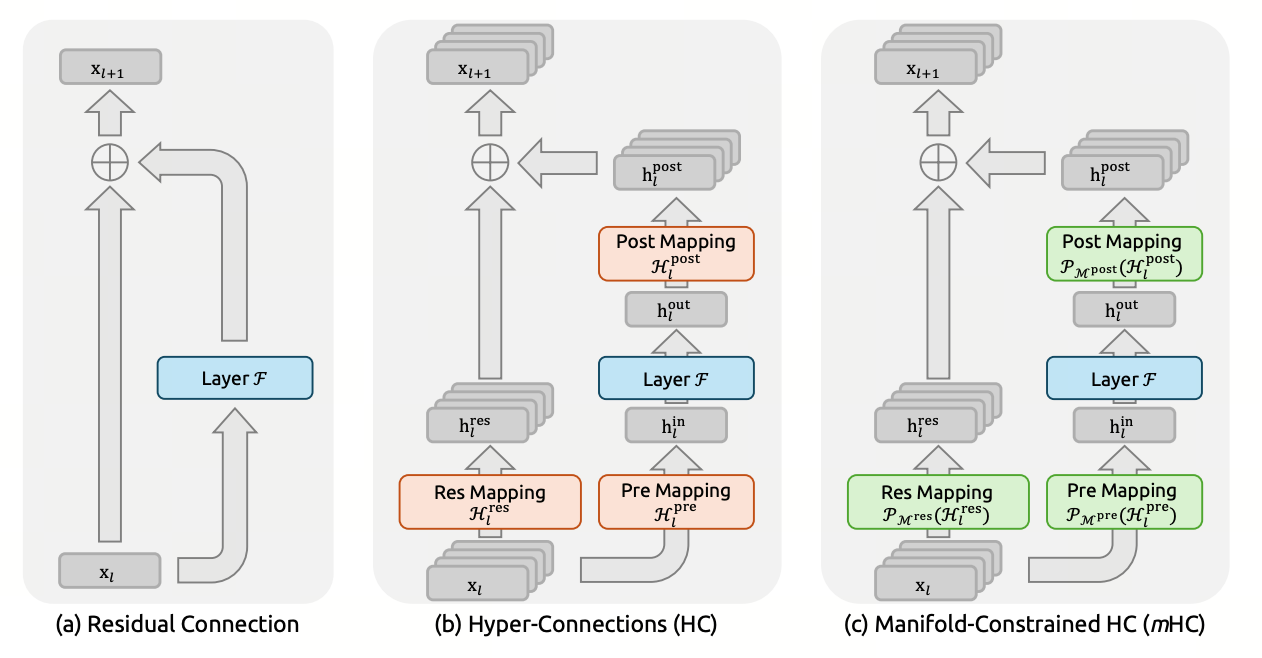
把"残差连接"从一根标量 highway 变成 $n_{hc}$ 条并行 highway,再把它们之间的"换道矩阵"强制关进一个不会放大输入的几何集合里。这就是 V4 在 60+ 层超深堆叠下还能稳得住的核心。
- 残差连接(Residual Connection)
- Transformer 里 $x_{l+1} = x_l + F_l(x_l)$ 那条"加法支路",让深网络的梯度能直接传回去。简单好用,但深度一上去,能量越加越大、异常值越传越远,是这一章一切麻烦的根源。
- Hyper-Connection(HC,Zhu 2025)
- 把单条残差扩成 $n_{hc}$ 条并行残差流(V4 取 $n_{hc}=4$)。每层多三个学习矩阵 $A_l, B_l, C_l$ 控制"读哪几条流 / 把输出写到哪几条流 / 流之间怎么混"。表达力上去了,但 $B_l$ 无约束 ⇒ 稳定性反而更差。
- Manifold(流形)
- 这里特指双随机矩阵的 Birkhoff 多面体 —— 所有"元素非负、行和为 1、列和为 1"的方阵构成的集合 $\mathcal M$。它有两个救命性质:里头任何矩阵的谱范数 $\le 1$,且乘法封闭(俩双随机矩阵相乘还是双随机)。
- Constrained(受约束)
- 把每层学到的"未约束"矩阵 $\tilde B_l$ 用 Sinkhorn-Knopp 迭代 20 步可微地投影回 $\mathcal M$。"可微"是关键 —— 反向传播能直接穿过去,整个 mHC 端到端可学。
1. 标准残差为什么扛不住 60 层
标准残差连接 $x_{l+1} = x_l + F_l(x_l)$ 看起来无害,但在大深度下有三个具体的失效模式:
- 能量累积:每个 $F_l$ 都向 $x$ 加一份贡献,$\|x_L\|$ 随 $L$ 增大单调上升。Pre-norm 能缓解但不能消除。
- 有效深度坍缩:当 $\|x_L\|$ 已经很大时,新加的 $F_L(x_L)$ 相对于累积的 $x_L$ 显得微不足道,后期层的贡献被淹没。模型名义 60 层,实际有效层数远小于 60。
- 异常值不可消除:残差路径是恒等映射,一旦某一层 $F_l$ 输出含 outlier,它会被原样复制到所有后续层。这是 LLM 训练中"激活异常值"问题的几何根源。
DeepSeek 团队在 V4-Pro 早期实验(深度 61)里直接撞上了这个问题。常见的解法是改 LayerNorm(DeepNorm、Sandwich-LN 等),但都是压住表象。V4 走了另一条路 —— 直接改残差的几何结构。
2. Hyper-Connection(Zhu 2025):把残差从向量扩成矩阵
核心想法:与其只有一条残差流(宽度 $d$),不如同时维护 $n_{hc}$ 条并行残差流(每条宽度 $d$),把整个 state 写成矩阵 $X_l \in \mathbb{R}^{n_{hc} \times d}$。每层引入三个学习矩阵 $A_l, B_l, C_l$ 控制流之间的读写:
每个矩阵的形状与角色:
| 符号 | 形状 | 角色 | V4 取值($n_{hc}=4, d=7168$) |
|---|---|---|---|
| $X_l$ | $n_{hc} \times d$ | 第 $l$ 层的"残差流矩阵",$n_{hc}$ 条并行 highway | $4 \times 7168$,每个 token 多带 4 份隐藏状态 |
| $A_l$ | $1 \times n_{hc}$ | 读:把 $n_{hc}$ 条流加权平均成单个 $d$-向量喂给 block | $1 \times 4$,4 个权重 |
| $F_l$ | $d \to d$ | 第 $l$ 层的实际计算(attention 或 FFN) | 原本 Transformer block 不变 |
| $C_l$ | $n_{hc} \times 1$ | 写:把 block 输出分发回 $n_{hc}$ 条流 | $4 \times 1$,4 个权重 |
| $B_l$ | $n_{hc} \times n_{hc}$ | 混合:流之间的相互交换矩阵 | $4 \times 4 = 16$ 个权重 |
$X_{l+1} = B_l X_l + C_l F_l(A_l X_l)$ 翻成大白话就是三步:
- 读:$A_l X_l$ —— 从 4 条 highway 上各取一点料,混成一份"输入"喂给本层 attention/FFN;
- 算:$F_l(\cdot)$ —— 本层正常计算,输出仍是 $d$ 维向量;
- 写 + 混合:$C_l \cdot \text{(输出)} + B_l X_l$ —— 一边把新结果按 $C_l$ 分发到 4 条流,一边按 $B_l$ 把旧的 4 条流重新"换道"打包。
整个过程比标准残差多了三个旋钮:选择从哪几条流读、写到哪几条流、流之间怎么换道。模型可以学会"这一层我把 outlier 关在第 3 条流里别让它污染主流"这种策略。
$n_{hc}$ 在 V4 取 4 —— 4 条 highway 之间允许"分工 + 兜底",例如某些流专门承载长程信号、另一些承载局部信号,$B_l$ 决定它们如何借换。
3. 但 HC 自己仍会"原地爆炸"
HC 的稳定性问题集中在 $B_l$。它是一个无约束的 $n_{hc} \times n_{hc}$ 矩阵,所有层堆起来后,从输入到输出的残差通路总变换是 $B_L \cdots B_2 B_1$。
定量看:
- 如果每层平均 $\|B_l\|_2 = 1.05$(仅高出 5%),60 层乘下来 $\|\prod B_l\|_2 \le 1.05^{60} \approx 18\times$ —— 残差路径放大 18 倍;
- 如果某些 $B_l$ 学出大的负值,相邻层流之间出现强相消,信息被洗掉;
- 训练初期 $B_l$ 几乎随机,谱半径分布很宽 —— 训练前几千步极其不稳。
这正是 DeepSeek 在 V4-Pro 早期跑出的现象。HC 本身没解决稳定性,只是把问题包装得更大。
拖滑条调整"每层无约束 HC 的谱范数"。红线 = 60 层堆叠后的累积放大;绿线 = mHC 强制每层 ≤ 1,无论怎么堆都不放大。把滑条拉到 1.05 看 L=60 的红线读数 —— 18 倍放大正是 V4-Pro 早期训练飘掉的根因。
4. mHC 的核心约束:把 $B_l$ 关进 Birkhoff 多面体
mHC(Manifold-constrained HC, Xie 2026)的关键一步:强制 $B_l$ 落在双随机矩阵的 Birkhoff 多面体上:
这个约束的含义拆开来看:
- $M_{ij} \ge 0$:每个流给下一层各流的"权重"都是非负的,禁止相消;
- $M\mathbf{1} = \mathbf{1}$:每行和为 1,每条流"分给"出去的总权重是 1,不放大;
- $\mathbf{1}^{T}M = \mathbf{1}^{T}$:每列和为 1,每条新流"接收"的总权重是 1,不浓缩。
反例:把右下角改成 1.5,行和变 1.9,列和也变 1.9 —— 不再双随机,谱范数会爆。
- 谱范数恒 $\le 1$:由 Birkhoff–von Neumann 定理,双随机矩阵 = 置换矩阵的凸组合。所有置换矩阵谱范数为 1,凸组合的谱范数 $\le 1$。所以 $\|B_l\|_2 \le 1$,$\|\prod B_l\|_2 \le 1$ 无论堆多深。
- 矩阵乘法下闭合:双随机矩阵的乘积仍然双随机。这意味着累积变换永远在合法集内,60 层和 6 层在几何稳定性上没有区别。
几何直观:把 4 条 highway 想成 4 个能量罐。$B_l$ 描述的是"这一步如何把 4 个罐里的水重新分配到 4 个新罐"—— 双随机约束保证总量守恒、不浓缩、不增减,最坏情况是所有水均匀混合($M = \tfrac{1}{n_{hc}} \mathbf{1}\mathbf{1}^T$),最理想情况是直接置换($M$ 是某个排列)。回到图 3-1 (c):那三个绿色 $\mathcal P_{\mathcal M}(\cdot)$ 框做的就是这件事,把 (b) 里的橙色 mapping 都打回这个集合。
$A_l, C_l$ 的处理:
- $A_l$ 用 $\mathrm{Sigmoid}$ 投到 $(0, 1)^{n_{hc}}$ —— 读流时禁止负权重,避免主信号被异号项相消;
- $C_l$ 用 $2\cdot\mathrm{Sigmoid}$ 投到 $(0, 2)^{n_{hc}}$ —— 写入流时给稍宽的动态范围,让 block 贡献能"压过去"。
5. 动态 + 静态参数化:让约束矩阵随上下文走
如果 $B_l$ 是固定的可学习参数,每层只有一个 $B_l$,它不能根据当前 token 调整流间路由。mHC 把它分解成静态 + 动态两部分:
每个符号:
- $\hat{X}_l$:当前层 RMSNorm 后的输入;
- $W^{\text{res}}_l$:把 $\hat{X}_l$ 投到 $n_{hc}^2$ 维的矩阵,$\mathrm{Mat}(\cdot)$ 把这个向量 reshape 成 $n_{hc} \times n_{hc}$;
- $\alpha^{\text{res}}_l$:可学习的标量系数,控制"动态部分"的权重;
- $S^{\text{res}}_l$:可学习的静态 $n_{hc} \times n_{hc}$ 矩阵,提供"默认混合模式"。
这条公式可以理解成"默认换道地图 + 一份按 token 微调":
- $S^{\text{res}}_l$ 是地图:每层有一份固定的"4 条 highway 默认怎么换道",训练初期主要靠它,模式简单稳定;
- $\hat X_l W^{\text{res}}_l$ 是实时路况:根据当前 token 内容动态生成一个补丁矩阵;
- $\alpha^{\text{res}}_l$ 是音量旋钮:训练初期取 ≈0.1,地图占主导;后期 $\alpha$ 学大,按 token 调整变得重要。
这种"先打地基再加上层建筑"的参数化,是双阶段训练稳定性的核心 —— 模型不会在第 0 步就被一个随机大动态项推飞。
$A_l, C_l$ 也用同样的动态+静态分解,公式形状相同,只是输出维度变成 $1\times n_{hc}$ 和 $n_{hc}\times 1$。
6. Sinkhorn-Knopp:把任意正矩阵打回多面体
$\tilde{B}_l$ 经过上述参数化后只是个普通矩阵,怎么可微地投到 Birkhoff 多面体上?mHC 的做法:
- 先取 $\exp(\tilde{B}_l)$,保证非负;
- 用 Sinkhorn-Knopp 迭代交替归一化行与列,20 步收敛到双随机矩阵。
其中 $\mathcal{T}_r$ 是行归一化(每行除以行和),$\mathcal{T}_c$ 是列归一化(每列除以列和)。
Sinkhorn-Knopp 干的事就两件,反复轮流:
- 把每一行除以它的行和 ⇒ 行和都变成 1(但列和被打乱);
- 把每一列除以它的列和 ⇒ 列和都变成 1(但行和又被打乱了一点点)。
每轮两边都被"打乱"得越来越轻,20 轮后行和列和都 ≈ 1,这就是双随机。重要的是这两步都是可微的元素级除法,autograd 能正常穿过去 —— 整个 mHC 仍然端到端可训。
初始矩阵是随机正矩阵(模拟 $\exp(\tilde B_l)$ 的输出)。每按"下一步"交替做一次行 / 列归一化。观察:3-5 步后两个残差就掉到 $10^{-3}$ 量级,10 步后基本归零。这就是 mHC 选 20 步迭代的安全边界。
经典定理(Sinkhorn 1964):任何全正矩阵在交替行列归一化下都收敛到双随机矩阵,且收敛是线性的(每次误差缩小 $\sim$ 常数比例)。 对 $4 \times 4$ 矩阵,10 步内残差就能降到 $10^{-4}$;20 步是充足的安全边界。
为什么不用 Hungarian 算法(求最优排列)? 因为它给出离散的硬置换,不可微,反向传播无法穿过它。Sinkhorn 是这个分配问题的软可微版本 —— 这也是它在 OT、attention sinkformer、RL 等领域被广泛使用的原因。
7. 代价 / 还没解决的问题
- Sinkhorn 计算开销:每层每步 20 次 $4\times 4$ 矩阵的行列归一化 $\approx$ 320 次乘除。相对 forward+backward 完全可忽略。
- 表达力损失:双随机 $4\times 4$ 矩阵构成 9 维流形(无约束是 16 维)。理论上表达力下降,但实测 loss 曲线不显著变化,反而稳定性大幅改善。
- 只约束了流间混合,没约束 $F_l$ 本身:mHC 让残差路径"非膨胀",但 $F_l$ 仍可能产生大幅 outlier。这部分由 Ch14 的 SwiGLU Clamping 与 Anticipatory Routing 兜底。
- $n_{hc}$ 必须不大:$n_{hc} = 4$ 是平衡点。若 $n_{hc} \to 16$,$B_l$ 矩阵变 $16\times 16$,Sinkhorn 仍 cheap,但动态参数化的 $W^{\text{res}}$ 投影维度从 16 涨到 256,参数量上升。V4 取 4 是工程权衡。
标准残差是无约束加法,60 层堆叠时能量与异常值都会累积。HC 把残差从向量扩成 $n_{hc}$ 条 highway,给每层三个旋钮(读 $A_l$ / 写 $C_l$ / 混合 $B_l$)。但 $B_l$ 无约束仍会爆炸,所以 mHC 把它关进双随机矩阵的 Birkhoff 多面体 —— 谱范数恒 $\le 1$ 且乘法封闭,60 层等同于 6 层的稳定性。代价是 9-vs-16 维表达力损失(实测无影响)和每层 20 步 Sinkhorn(开销可忽略)。
shape n_hc × d"] --> Norm["RMSNorm + flatten"] Norm --> Aw["A_l 通道"] Norm --> Bw["B_l 通道"] Norm --> Cw["C_l 通道"] Aw -- "Sigmoid" --> A["A_l ∈ (0,1)"] Cw -- "2·Sigmoid" --> C["C_l ∈ (0,2)"] Bw -- "exp" --> Bp["正矩阵"] Bp -- "Sinkhorn-Knopp ×20" --> B["B_l ∈ Birkhoff"] A --> F["Layer F_l"] F --> C C --> Add(("+")) X --> B B --> Add Add --> Xn["X_(l+1)"] classDef key fill:#71a4e1,stroke:#71a4e1,color:#fff class B,A,C key
图 3-2 · mHC 的动态参数化流程。Sinkhorn-Knopp 是把残差矩阵"打回流形"的关键一步,保证累积变换的谱范数永远 $\le 1$。