MegaMoE — 让 all-to-all 消失
为什么 MoE 在专家并行下天然被通信卡死,V4 是怎么把 5 个阶段切 wave 流水让"通信完全藏在计算下面",以及那条 $C/B \le 6144$ FLOPs/Byte 的硬件协设公式到底在说什么。
MegaMoE = 把 MoE 的 dispatch / L1 / Activation / L2 / combine 五个阶段融成一个 pipelined kernel,用"专家波(wave)"为粒度调度
一句话:把"通信"和"计算"切成多个等长 wave 交错排队,第一个 wave 在 GPU 算的同时,第二个 wave 已经在网络上传,于是 all-to-all 的 latency 完全被矩阵乘的 latency 盖住 —— 净效果就像 all-to-all 不存在。 最高 1.92× 理论加速,对应一条给硬件厂商的硬性建议:每 GBps 互联带宽要养 6.1 TFLOP/s 计算。
- EP(Expert Parallelism · 专家并行)
- MoE 的标准切法:把 $E$ 个专家分散到 $G$ 个 GPU,每张卡只放 $E/G$ 个专家。每个 token 的 router 选 top-$k$ 后必须把 token 发去那 $k$ 个专家所在的卡,算完再收回来 —— 这就是为什么 MoE 一定要 all-to-all。
- all-to-all
- 每张卡都给所有其他卡发数据、同时也从所有其他卡收数据的集合通信。带宽随卡数线性增长,但 latency 不降,是 MoE 的头号瓶颈。一次 1.6T MoE 的 forward 要做 2 次(dispatch + combine),backward 还要 2 次。
- Dispatch / L1 / Activation / L2 / Combine(MoE 5 段)
- Dispatch:按 router 决定把 token 发到目标专家的卡上(all-to-all 1);L1:专家 FFN 的 up 投影 + activation 输入;Activation:SwiGLU 等非线性;L2:down 投影;Combine:把结果发回原 token 所在的卡(all-to-all 2)。这 5 段在 naive 实现下是串行的。
- Wave(专家波)
- 把本次 batch 命中的专家切成若干组,每组里包含 $w$ 个专家。Wave-by-wave 流水:第 $i$ 个 wave 在算 L1 时,第 $i+1$ 个 wave 已经在做 dispatch;第 $i$ 个 wave 在做 combine 时,第 $i-1$ 个 wave 的 combine 早就发完。wave 数 ↑ → 流水深度 ↑ → 隐藏越彻底,但每段单次量越小、效率↓。
- Comet(前驱方案,被 MegaMoE 替掉的对象)
- 2024 年的 fused MoE 方案,把 5 段切成 3 段并行(dispatch + L1 / activation + L2 / combine)。问题:只有 3 段,流水深度浅,combine 阶段 GPU 计算单元闲;wave 概念没引入,长尾专家拖整体。MegaMoE 在 Comet 基础上加 wave 调度 + 5 段切,深度从 3 加到 5+。
- C/B 比(Compute-to-Bandwidth Ratio)
- 每发出 1 字节需要伴随多少 FLOPs 的计算才能"刚好"覆盖该字节的传输时间。$C/B = 2d$,$d$ 是 hidden dim。V4 取 $d=3072$(FFN 中 token 维),所以阈值 $= 6144$ FLOPs/Byte。这是给 GPU 厂商的硬件协设公式:超过这个值,再堆带宽是浪费。
- Pull vs Push(通信原语)
- Push = 我主动把 token 推给目标卡;Pull = 我准备好 token,目标卡来取。细粒度通信下 pull 更友好:发起方不用知道接收方何时空闲,接收方按自己节拍取,避免 push-side 排队等握手。MegaMoE 使用 NVLink/IBGDA pull 模式。
- SwiGLU 简化(拿掉 exp/div)
- 标准 SwiGLU $= x\cdot\sigma(Wx)\cdot Vx$ 含 sigmoid。把它换成 $x\cdot Wx \cdot Vx$(不带 σ)能省掉 exp 与 div,放更大中间维 d 还能保精度 —— 是 MegaMoE 给硬件的另一个建议。
1. 为什么 MoE 一定卡在 all-to-all
要理解 MegaMoE 为什么必要,先看 MoE 在 EP 下的原始时间线。设单 token 从进入 MoE 层到离开,要走五步:dispatch(all-to-all 1)→ L1(FFN up 投影)→ Activation(SwiGLU)→ L2(FFN down 投影)→ combine(all-to-all 2)。 每段都不能并行:dispatch 没完,L1 没数据;L2 没完,combine 没数据。
把"一次 MoE forward 时间"列成最朴素的式子:
- $T_{\text{disp}} + T_{\text{comb}}$:纯通信时间,由互联带宽 $B$决定(NVLink ~900 GB/s,IB ~50 GB/s);
- $T_{L_1} + T_{L_2}$:纯计算时间,由GPU FLOPs $C$ 决定(H100 BF16 ~989 TFLOPs/s);
- $T_{\text{act}}$:通常很小,可忽略。
问题:通信和计算串行加总,只要其中一段慢,整体就慢。MoE 实测里 $T_{\text{comm}}/T_{\text{compute}}$ 常 $\ge 1$ —— 也就是通信花的时间和计算一样多甚至更多,相当于 GPU 一半时间在等网络。
一层 FFN 计算 ~$2 \times 4096 \times 3072 \times 12288 \times 8 \approx 2.5 \times 10^{12}$ FLOPs,H100 989 TFLOPs/s → $T_{\text{compute}} \approx 2.5\,\text{ms}$。
看起来通信只占 480/(480+2500) ≈ 16%。但 V4 里有 ~30 个 MoE 层,每层 forward + backward 各 2 次 all-to-all,累计: 30×4×480 = 57.6 ms 纯通信。一个完整 step ~1 s,单是 MoE 通信占了 5–6%。再加上 dense 的 TP/PP 通信、router 的 ranking、长上下文 CP,通信总占比常 30%+。训练只跑 70% 的有效计算时间。这就是 MegaMoE 想要回收的部分。
2. 前驱:Comet 把 3 段并行
MegaMoE 不是凭空出现的。2024 年的 Comet 已经把 MoE 5 段并到 3 段:
- Stage 1: dispatch + L1(dispatch 在做的同时,已收到的部分 token 立刻进 L1)
- Stage 2: activation + L2
- Stage 3: combine
Comet 的问题是 流水深度只有 3 —— combine 是末尾,没人和它并行;而且没有"专家粒度"的概念,长尾专家(被极少 token 命中的专家)会让某个 stage 拖整体。MegaMoE 在 Comet 基础上做两件事:
- 切深:把 5 段都暴露出来分别调度,流水深度从 3 加到 5+;
- 切细:把"专家"切成 wave,每个 wave 是几个专家的集合,wave-by-wave 流水。
3. Wave 调度:让通信完全藏在计算下面
关键的工程 trick:把本次 batch 命中的专家分组成 $W$ 个 wave,每个 wave 包含 $E_{\text{hit}}/W$ 个专家。每个 wave 单独跑一遍 5 段,但相邻 wave 的段错位排队:
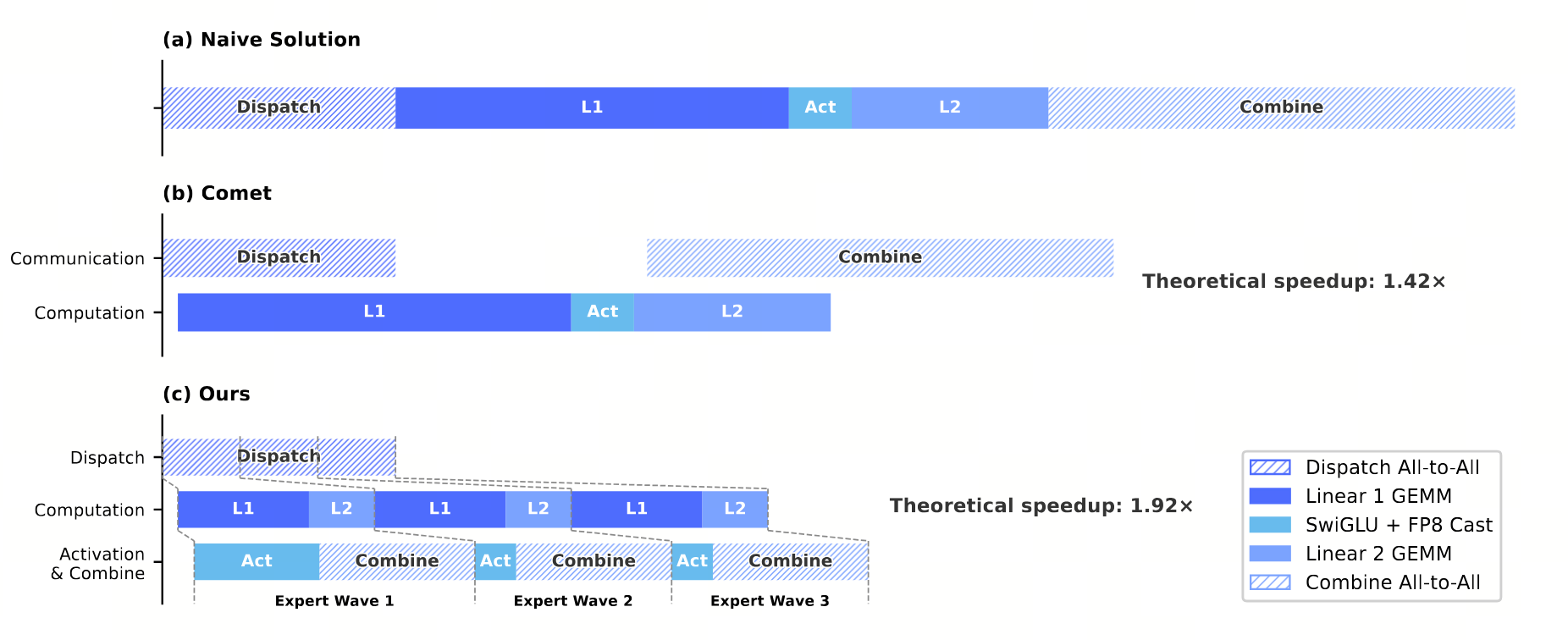
读图法:上方是 naive 串行(5 段排队加总),下方是 MegaMoE 切 $W$ 个 wave 后的时间线。每个 wave 自己内部仍然串行(5 段),但相邻 wave 的同型段错位:wave 2 的 dispatch 在 wave 1 还在做 L1 时就发出去了,wave 3 的 L1 在 wave 2 算 L2 时已经在 GPU 上跑。
$W$ 越大,时间线越紧凑(隐藏越彻底),但每段单次量变小 —— 太碎会让矩阵乘的 tile 利用率掉、IB latency 占主导。所以 $W$ 在论文里取 4–6 之间。
数学上,naive 总时间 $T_{\text{naive}} = 5T$(设每段都耗 $T$)。MegaMoE 按 $W$ 个 wave 流水,最佳情况下每多一个 wave 只多 $T$(最后填满管线):
$W \to \infty$ 时下限 $T$,5× 的渐近加速。但实测最高只到 1.92×,因为 $W$ 大到一定程度后通信粒度太碎,IB latency 与 wave overhead 反吃掉收益。
4. 那条公式:$C/B \le 6144$ FLOPs/Byte
MegaMoE 之所以能"通信被计算完全覆盖",前提是本次计算的时间 $\ge$ 本次通信的时间。换算成单位字节:每发 1 字节,要伴随足够的 FLOPs 让计算时间盖住通信。把这个写成不等式:
推导左边:单 wave 一段 L1 要算 $2 \cdot s \cdot d \cdot d_{\text{ff}}$ FLOPs($s$ token 数,$d$ hidden,$d_{\text{ff}}$ 中间维),通信传 $s \cdot d$ Bytes(BF16 一个数 2 字节,但比例上抵消)。化简后每字节对应 $2d$ FLOPs。代入 $d=3072$:
$C/B \le 2d = 6144$ FLOPs/Byte 翻译成大白话就是:
- 左边 $C$(每秒能算多少)÷ $B$(每秒能传多少):硬件提供的"每字节配多少 FLOPs";
- 右边 $2d$:MoE 工作负载真正需要的"每字节多少 FLOPs";
- $\le$ 关系:硬件给的算力配比 ≤ 工作负载需要的,说明计算还能跟上通信,可以靠 wave 流水把通信藏起来。
反过来如果硬件 $C/B \gg 6144$(GPU 计算太快、互联太慢),那么再切多少 wave、再 fuse 多少 kernel,都无法把通信藏住 —— 这时只能加带宽。这就是给硬件厂商的"目标线":把 $C/B$ 做到 ~6144,再多就是浪费 silicon。
- H100 + NVLink(节点内):$C=989$ TFLOPs/s, $B=900$ GB/s → $C/B \approx 1099$。远低于 6144 —— 节点内 MegaMoE 能完美 overlap,通信几乎不可见。
- H100 + InfiniBand 400G(节点间):$B \approx 50$ GB/s → $C/B \approx 19{,}780$。远高于 6144 —— 跨节点 EP 时通信暴露,wave 也藏不住。这就是为什么 V4 的 MoE 几乎都尽量在节点内做 EP,跨节点用 PP/CP。
- 下一代理想互联:$C/B \approx 6000$ → 跨节点 MoE 也能 overlap。论文呼吁"每 GBps 配 6 TFLOPs/s",意思是这个比例。
5. 给硬件的四条建议(论文 §3.1, p. 16)
- 计算-通信比 $C/B \approx 2d \approx 6144$:上面已展开,不要无脑堆带宽,目标是 ~6 TFLOP/s/GBps。
- 功耗预算:MegaMoE 把 compute / mem / net 同时拉到 80%+,极端融合下 GPU 会进入 power-cap。要留 power headroom,不然 SM 会自动降频反吃 wave 流水的收益。
- 通信原语:pull > push:细粒度 wave 通信里,pull 模式的接收方按自己节拍取,避免发起方的握手等待。NVIDIA IBGDA 的 GPU-initiated put 也算 pull 风格。
- 激活函数:拿掉 SwiGLU 的 exp/div:把 $\sigma(\cdot)$ 换成线性门控,能省 ~30% 的 activation 算力,把这部分算力分给更大的 $d_{\text{ff}}$ 在精度上反而更划算。
6. 三方对比 · 看时间游标比终点
上面是静态推导。下面这张动态甘特图把同一批 token、同一层 MoE,分别跑 naive / Comet / MegaMoE 三种调度,让一条红色"当前时刻"游标从左扫到右。看哪一行最先抵达虚线,就是哪种最快。
给初学者:三排对应三种调度,同色块代表同一阶段(黄=Disp, 蓝=L1, 紫=Act, 绿=L2, 橙=Comb)。游标走到哪、哪段就被"激活"了。绿色虚线是各自的终点。
给研究者:critical path 长度对照公式 —— Naive $=5T$;Comet 单 wave $\approx 3T$;MegaMoE $=T(1+4/W)$。把 W 推到 6 时 MegaMoE 行已被压扁到几乎只剩一格 —— 但论文实测只到 1.92×,差距来自 wave overhead(每 wave 启动 / 同步开销),这是 W 不能无限大的理由。
另一面,前面 §4 那条 $C/B \le 6144$ 不是孤立的数字,它和"通信被覆盖的比例"是一一对应的关系:硬件提供的 $C/B$ 比工作负载需要的 6144 大多少倍,暴露的通信就有多少。下图把这层关系画成一条曲线。
读图法:蓝色曲线是 overlap 上限 $= \min(1, 6144 / C{:}B_{\text{硬件}})$。绿色点(NVLink)落在曲线"平台段",意味着 wave 流水可以把通信几乎全藏住;橙色点(IB400G)跌到 31%,意味着即便 MegaMoE 全开,跨节点跑还有 69% 通信会暴露 —— 这就是 V4 训练时尽量把 EP 关在节点内的物理理由。粉色阴影区是"无论怎么调度都救不回来"的暴露区。
研究者注意:曲线在 C/B=6144 后是双曲线 $1/x$ 衰减,所以"加一倍带宽"(C/B 减半)从 20k → 10k 时 overlap 从 31% 涨到 61%,边际收益巨大;但从 4k → 2k 收益为零(已封顶)。这解释了为什么 NVLink 加宽到 1.8 TB/s 几乎没收益、而 IB 加宽到 800G 收益明显。
本章小结
- MoE 在 EP 下天然被 all-to-all 卡死:通信和计算串行,naive 实现下通信占 30%+ wall-time。
- Comet 把 5 段并到 3 段,MegaMoE 进一步切 wave 让流水深度到 5+,实测 1.92× 加速。
- $C/B \le 2d = 6144$ FLOPs/Byte 是"通信能被计算完全覆盖"的临界条件,超过它再加带宽是浪费。
- 四条硬件建议(C/B、power、pull、SwiGLU 简化)是 DeepSeek 把训练经验反向输给芯片厂商的尝试。