推理框架 — KV 的异构调度
为什么 SWA / CSA / HCA / Indexer 四种 KV 不能共用 PagedAttention 的统一布局,V4 的 State Cache + Block Cache 二分设计怎么把"位置敏感的尾巴"与"压缩好的躯干"分别管理,以及盘上 KV 缓存怎么让百万 token 的 prefill 在共享前缀下接近免费。
推理框架要解决:(1) V4 各层 KV 形状各异(SWA 1×、CSA 1/m、HCA 1/m'、Indexer 极小),统一 page 装不下;(2) SWA 有"窗口外即丢"的过期策略与 page 通用回收冲突;(3) 1M 上下文下盘上 KV 复用前缀
一句话:把 KV cache 切成 State Cache(位置敏感、按请求分配)和 Block Cache(压缩好、按 lcm(m, m') 对齐分块),两者协议解耦。共享前缀(system prompt、文档查询)盘上落地,命中后直接 map 进 GPU 跳过整段 prefill。 净效果:1M 上下文 prefill 在 cache 命中时几乎免费,未命中时 SWA 与压缩 KV 的存量比例与训练对齐,不破坏 logits bit-identity。
- KV Cache
- Transformer 推理的核心结构:每一层每一 token 的 key/value 存下来供后续 token 查 attention。体积线性增长于序列长度,1M token 单层 ~1MB → 全模型 ~60MB/请求 → 万人并发时 ~3.6TB。是百万级上下文的头号瓶颈。
- SWA / CSA / HCA / Indexer 四类 KV
- SWA(滑窗):每层只存最近 $n_{\text{win}}=4096$ token,位置强相关(窗口外即丢);CSA(压缩 + 稀疏):每 $m=4$ token 压成 1 个;HCA(重压缩):每 $m'=128$ token 压成 1 个;Indexer:极小 K-only,用于 top-k 选择。四种形状、四种策略,无法共用 page。
- PagedAttention(vLLM 经典方案)
- 把 KV cache 切成固定大小的 page(如 16 token / page),所有请求共享一个大 page pool,新请求就从 free list 拿、释放就还回。简单高效,但假设所有层 KV 同构。V4 一上来就破坏这个假设。
- State Cache(V4 的位置敏感缓存)
- 装对位置敏感的部分:SWA 当前窗口、CSA/HCA 还没压缩满的尾部 token。按"请求 → 状态块"映射,请求结束就释放整块。不与其他请求共享。这是 V4 把"位置敏感性"显式表达的设计。
- Block Cache(V4 的压缩好缓存)
- 装已经压缩完成的 KV:CSA 压缩条目、HCA 压缩条目、Indexer K。按 $\mathrm{lcm}(m, m') = \mathrm{lcm}(4, 128) = 128$ 对齐分块,每块产出 $k_1 = 32$ 个 CSA + $k_2 = 1$ 个 HCA 条目。可跨请求共享(前缀复用)。
- lcm(m, m') 对齐分块
- CSA 每 4 token 一压、HCA 每 128 token 一压。两个边界都要落到 block 边界 → block 大小必须是 $\mathrm{lcm}(4, 128) = 128$。每个 block 输入 128 个 token、输出 32+1 个压缩条目。这个对齐是 kernel 与 cache 协同的硬约束。
- 过期策略冲突
- SWA 有"窗口外即丢"的过期:滑窗向前推 1 token,最早的 token 就要清除。Page 通用回收没有这个语义 —— 它只在请求结束时回收,SWA 中间过期的 page 无法回收。所以 SWA 必须独立管理。
- 盘上 KV(Disk-resident KV cache)
- 把已计算的压缩 KV 序列化到 SSD,命中时 mmap + GPU async copy 进显存,跳过整段 prefill。共享前缀(system prompt、长文档 RAG)命中率极高,对长上下文是救命稻草。
- 三档 SWA 缓存策略
- Full SWA Caching:每个请求 SWA 全落盘。最快但 SSD 写入压力大;Periodic Checkpointing:每 $p$ 个 token 落一次盘,命中后只重算 tail;Zero SWA Caching:不存 SWA,命中时仅靠 CSA/HCA 重算最后 $n_{\text{win}}\cdot L$ 个 token。三档对应不同存储 / 算力权衡。
1. PagedAttention 在 V4 下为什么不够用
PagedAttention 的优雅在于"把 KV 看作通用 page"。这件事在 V3 / Llama 时代成立,因为所有层都是同一种 attention,KV 形状统一。V4 改变了这个前提:
- SWA 层:$d_h \cdot n_{\text{heads}} = 128 \times 16 = 2048$ B(K + V 各 1024);
- CSA 层(每 4 token 压 1):$2048 / 4 = 512$ B 压缩条目(摊分);
- HCA 层(每 128 token 压 1):$2048 / 128 = 16$ B 压缩条目;
- Indexer K-only:$d_k \cdot n_{\text{heads}}^{\text{idx}} = 64 \times 4 = 256$ B(只存 K,FP4)= 16 B 实际;
- 体积差异 128×:上面这条;
- 过期策略冲突:SWA 滑窗外即丢,page 不知道何时回收;
- kernel 对齐:CSA / HCA 的稀疏 attention kernel 要求 cache line 按 lcm(4, 128) 对齐,与 page 的 16 token 边界不兼容;
- 压缩边界:CSA / HCA 的压缩计算横跨 page 边界,page 的"独立单元"假设破坏。
2. V4 的二分设计:State Cache + Block Cache
2.1 State Cache:位置敏感的尾巴
State Cache 装两类东西:
- SWA 当前窗口:每层最近 $n_{\text{win}}=4096$ token 的 K/V;
- 压缩尾部:CSA / HCA 还没压满 $m$ / $m'$ 个 token 的尾段(称 "in-flight tail");
按请求生命周期分配:每请求一开始申请 1 个 State Block(约 60MB),请求结束整块释放。不与其他请求共享。这样过期问题、生命周期问题、对齐问题都内化到单个 State Block 内部,对外只暴露"请求级"的接口。
2.2 Block Cache:压缩好的躯干
Block Cache 装已压缩的:
- CSA 压缩条目(每 4 token 1 个);
- HCA 压缩条目(每 128 token 1 个);
- Indexer K(每 token 1 个 FP4 K-only);
按 $\mathrm{lcm}(4, 128) = 128$ 对齐分块。每个 Block 输入 128 token,输出 32 个 CSA + 1 个 HCA + 128 个 Indexer K。Block Cache 可跨请求共享 —— 只要前缀相同,多个请求引用同一个 Block,refcount 管理。
$m = 4$, $m' = 128$。要让 CSA 边界(每 4)与 HCA 边界(每 128)同时落到 block 边界:
- $\mathrm{lcm}$ 是最小公倍数:能被 $m$ 整除(CSA 边界对齐),也能被 $m'$ 整除(HCA 边界对齐);
- 每 block 输出:CSA 条目 = $128 / 4 = 32$ 个;HCA 条目 = $128/128 = 1$ 个;
- 如果 $m, m'$ 互素,$\mathrm{lcm} = m \cdot m'$;本例 $m | m'$ 所以 $\mathrm{lcm} = m'$。
这条对齐是kernel 与 cache 协同的硬约束:sparse attention kernel 假设访问的压缩条目按 cache line 对齐,错位会触发额外 load + reorder。block size 选 lcm 让"一个 block 是一个 kernel iteration 的最小单元",同时 SWA 窗口 4096 也是 lcm 的整数倍 ($4096 = 32 \times 128$),三者锁死。
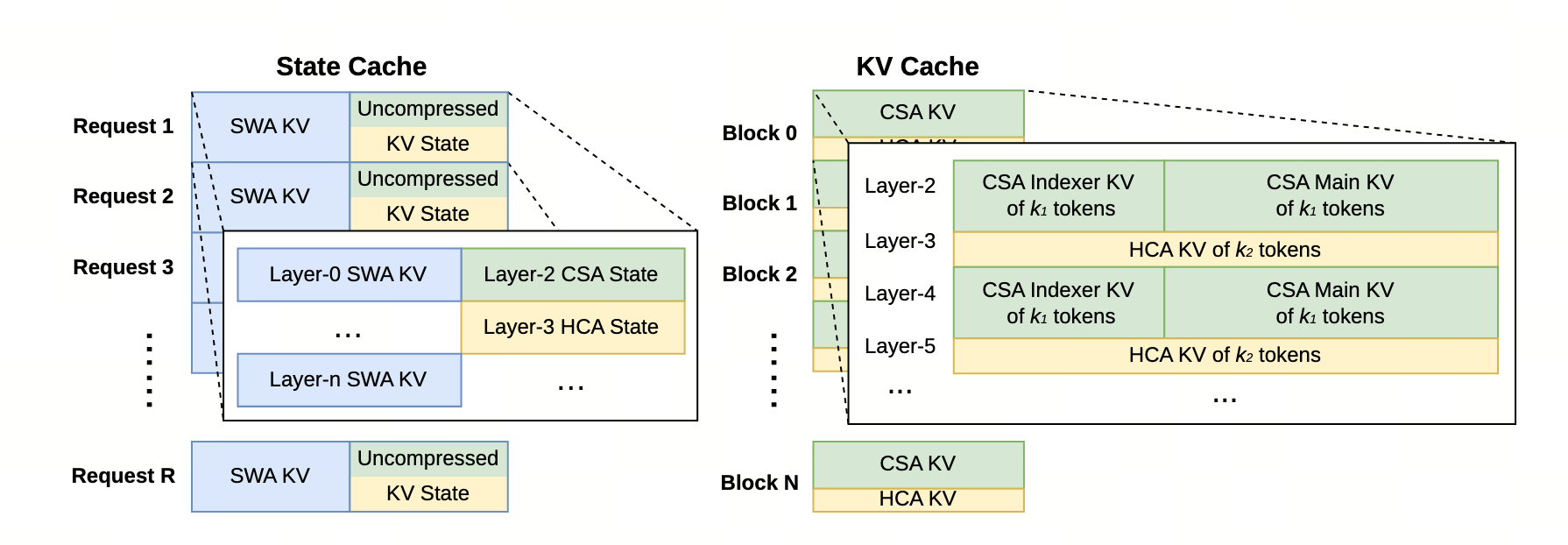
读图法:上排是 Block Cache —— 每 128 token 凑成一块,块内 32 个绿条(CSA)+ 1 个蓝条(HCA)。这部分可跨请求共享,前缀命中时直接 mmap 进显存。
下排是 State Cache —— 黄段是 SWA 4096 窗口(每请求独占),橙段是不足 128 还没压成的 in-flight tail。请求结束整块释放。不在跨请求共享池里。
把 token 数从 8192 拉到 32768 你会看到 block 数线性增长但 State Cache 体积几乎不变(SWA 窗口固定 4096 + tail ≤ 128)—— 这就是 V4 长上下文不爆显存的本质:百万 token 几乎全部进 Block Cache(压缩 32×~128×),State Cache 永远是 ~5K token 的固定占用。
3. 盘上 KV:让百万 token 的 prefill 在共享前缀下接近免费
长上下文应用的典型 pattern:
- System prompt:每请求都带的几千 token 引导词;
- RAG / 文档问答:同一文档反复被多个 query 查;
- Code agent:同一仓库被多次 attach;
这些前缀跨请求重复,每次都从头 prefill 是巨大浪费。V4 把压缩好的 Block Cache 序列化到 SSD:
- 请求开始时,对 prompt 哈希 → 查 SSD 是否有命中;
- 命中 → mmap + GPU async copy 进显存,跳过整段 prefill;
- 未命中 → 正常 prefill 后落盘,下次命中。
- 无盘上 KV:每次 1M prefill ≈ 30 秒 × 100 query = 3000 秒 GPU;
- 盘上 KV 命中:第 1 次 30 秒 + 落盘 ~5 秒;后 99 次 mmap + load ~2 秒 = 30 + 99 × 2 ≈ 230 秒;
- 13× 加速。Block Cache 大小 ~60MB / 1M token,1TB SSD 能存 16K 个 1M 上下文。
3.1 SWA 三档策略
Block Cache 落盘很简单(已压缩,体积小)。State Cache 难处理:SWA 是位置敏感的,落盘后下次命中时位置可能不一样。三档策略:
- Full SWA Caching:每层 SWA 全落盘。最快命中,但 SSD 写入压力大(一个请求写 ~25GB SWA / 1M ctx);
- Periodic Checkpointing:每 $p = 16384$ token 落一次盘,命中后从最近 checkpoint 重算 tail(最多重算 $p$ token)。SSD 写入 ÷ p,重算开销小;
- Zero SWA Caching:完全不存 SWA,命中时仅靠 Block Cache 中的 CSA/HCA 重算最后 $n_{\text{win}} \cdot L = 4096 \times 61 \approx 250K$ token 的 SWA。零 SSD 占用,但每次命中都要 ~10 秒重算。
典型部署:长文档查询用 Periodic Checkpointing(命中频繁、重算可控),冷请求用 Zero(占用最小)。
本章小结
- PagedAttention 假设所有层 KV 同构、可独立回收。V4 四类 KV(SWA / CSA / HCA / Indexer)体积比 128:32:1:1,过期策略不同,必须分治。
- State Cache:位置敏感的 SWA + in-flight tail,按请求分配;Block Cache:压缩好的 CSA / HCA / Indexer K,按 $\mathrm{lcm}(4, 128) = 128$ 分块,跨请求共享。
- 百万 token 几乎全进 Block Cache(压缩 32–128×),State Cache 固定 ~5K token —— 显存随上下文长度近似常数增长。
- 盘上 KV + SWA 三档策略让共享前缀场景 prefill 接近免费,13× 加速级别。
- 这套设计与 Ch11 的 two-stage CP 是训推对偶:训练时跨 CP rank 桥接压缩边界,推理时跨请求共享压缩 block。压缩这一动作是 V4 的统一原语。