Tool 接口三件套 — 工具调用的语法
为什么 V4 不用 JSON 做 tool-call 而自创 DSML 专用 token,"跨轮保留 thinking"在长 horizon Agent 里到底解决了什么具体问题,以及"把判定型小任务编码成 token 而非小模型"这条工程哲学怎么把 TTFT 推到接近 0。
三件套 = (1) DSML 专用 token schema 替代 JSON 工具调用;(2) Interleaved Thinking 在 tool-calling 模式下跨轮保留 thinking trace;(3) Quick Instruction 把 6 个判定型小任务编码成特殊 token 共享主 KV
一句话:把 agentic 工作流"塞进同一份 KV"。 JSON / 独立小模型 / thinking 重置 这三件事在 V3 时代各是一个"控制平面之外的额外组件";V4 把它们全部内化成 token 序列层面的结构,于是 tool-call 不再有转义问题、Agent 多轮不再丢解题状态、辅助任务不再需要独立模型。
- JSON Tool-Call(被替代的对象)
- OpenAI / Anthropic 标准做法:让模型生成
{"name": "search", "args": {...}}的 JSON 字符串。问题:(1) JSON 的引号 / 转义 / 嵌套对 LLM 是高失败率任务(实测 5-15% 转义错误);(2) 字符串解析靠正则或括号配对,一个不匹配整段调用就废;(3) JSON 与文本混在同一字符流里,分隔靠 prompt 约定,没有 token 层面的硬边界。 - DSML(DeepSeek Markup Language,Table 4)
- V4 自创的工具调用 schema,用专用 token(如
<|DSML|tool_calls><|DSML|invoke><|DSML|parameter>)作为分隔符。每个开闭标签是 1 个 token,不参与 BBPE 拼接 —— 模型生成它就是有意"调用工具",不可能因转义错误生出。XML 风格但不是真 XML(不需要解析器,只需切 token)。 - Interleaved Thinking(跨轮保留思考)
- 多轮 Agent 任务里,新一轮 user message 到来时是否丢弃上一轮的 thinking。V3.2:丢弃。V4 在tool-calling 模式下:全部保留,跨 user message 边界也保留。动机:long-horizon 任务里"我之前为什么选这条路"是关键解题状态,丢了下一轮就要重做。
- Long-Horizon Agent
- 需要 10-100+ 轮工具调用才能完成的任务(debug 仓库、跨文件重构、多步研究)。每轮丢弃 thinking 的代价:随轮次线性累积,第 50 轮要从 0 重新建立解题状态,TTFT 与质量双输。
- Tool-Calling Mode(专用模式)
- V4 区分 普通对话 vs tool-calling 两个模式。普通对话仍丢弃旧 thinking(避免 context 被无关思考拖累);tool-calling 触发 thinking 保留模式。模式切换由 system prompt + tool-call schema 共同决定。
- Quick Instruction
- chatbot pipeline 里正式答复前的判定型小任务:是否联网、query 改写、意图分类、URL 是否抓取等。V4 把每个任务编码成 1 个特殊 token,附在主 prompt 尾部。主 KV 已 prefill 好,附加 token 直接共享 KV,零额外 prefill。
- TTFT(Time To First Token)
- 用户提交 prompt 到看见第一个 token 的延迟。主导因素:prompt prefill 时间(O(n²) 注意力)。独立小模型方案需要单独 prefill 一遍 prompt → TTFT 翻倍;Quick Instruction 共享主 KV → TTFT 几乎不增加。
- 控制平面 vs 数据平面(系统设计术语)
- 数据平面:模型 forward 的 token 流;控制平面:决定该走哪条路、该调什么工具的"判定逻辑"。传统做法把控制平面放在外部代码 / 独立小模型,每个判定要单独 inference。V4 把控制平面嵌入数据平面 —— 用 token 表达控制信号。"少一个进程比少一个 layer 更值钱"。
- KV Cache 共享
- 主 prompt 已经 prefill 后,KV 矩阵就在 GPU 里。Quick Instruction token 追加在尾部时,前面 KV 不变,只需算这一个 token 的 attention。增量成本 ≈ 1 token decode,相比一次 full prefill 是 1000× 加速。
1. DSML:把 tool-call 从字符串升级为 token
先看 OpenAI 风格的 JSON tool-call 在 V4 规模下的具体痛点:
- 引号转义错误(如
"path": "C:\Users"缺反斜杠):~3% 调用 - 括号 / 大括号不匹配(嵌套深 ≥ 3 层时 LLM 容易少一个):~5% 调用
- 非法 JSON(含未转义换行、控制字符):~2% 调用
- 合计 ~10% 调用解析失败,长 horizon 任务里 50 轮就有 ~99.5% 概率至少踩一次。
DSML 的解法是在 token 层面定义 schema。每个开闭标签(<|DSML|tool_calls>、<|DSML|invoke>、<|DSML|parameter> 等)都是词表里的单一 token,模型要"调工具"就生成这个 token,不可能因为转义出错。
论文 Table 4 给出的 schema 模板(去除占位符):
<|DSML|tool_calls>
<|DSML|invoke name="$TOOL_NAME">
<|DSML|parameter name="$KEY" string="true|false">$VALUE<|DSML|parameter>
...
<|DSML|invoke>
<|DSML|tool_calls>三个细节一起作用:
- 专用 token 不参与 BBPE:普通字符串里的
<|DSML|...>子串不会被 tokenizer 切成同一个特殊 token —— 它是词表中预留的 fixed-id token,只有解码器主动选它才会出现。这是从根上消掉"字符串拼接出错"的可能性; - parameter 用 string="true|false" 标注类型:
true表示按字面量传(处理路径、long string),false表示值是 JSON(数字 / bool / 数组 / 对象)。把"类型决策"显式化,避免 LLM 自己脑补; - tool-call 块强制夹在 thinking 之外:
<think>…</think>段不允许出现 DSML token —— 思考归思考,执行归执行,分得清清楚楚。这条约束在 SFT 数据里被严格执行,模型自然学会。
合起来:调用解析失败率从 ~10% 降到接近 0(实测 < 0.1%),残留的失败几乎都是"工具不存在"或"参数语义错",不再是"格式错"。
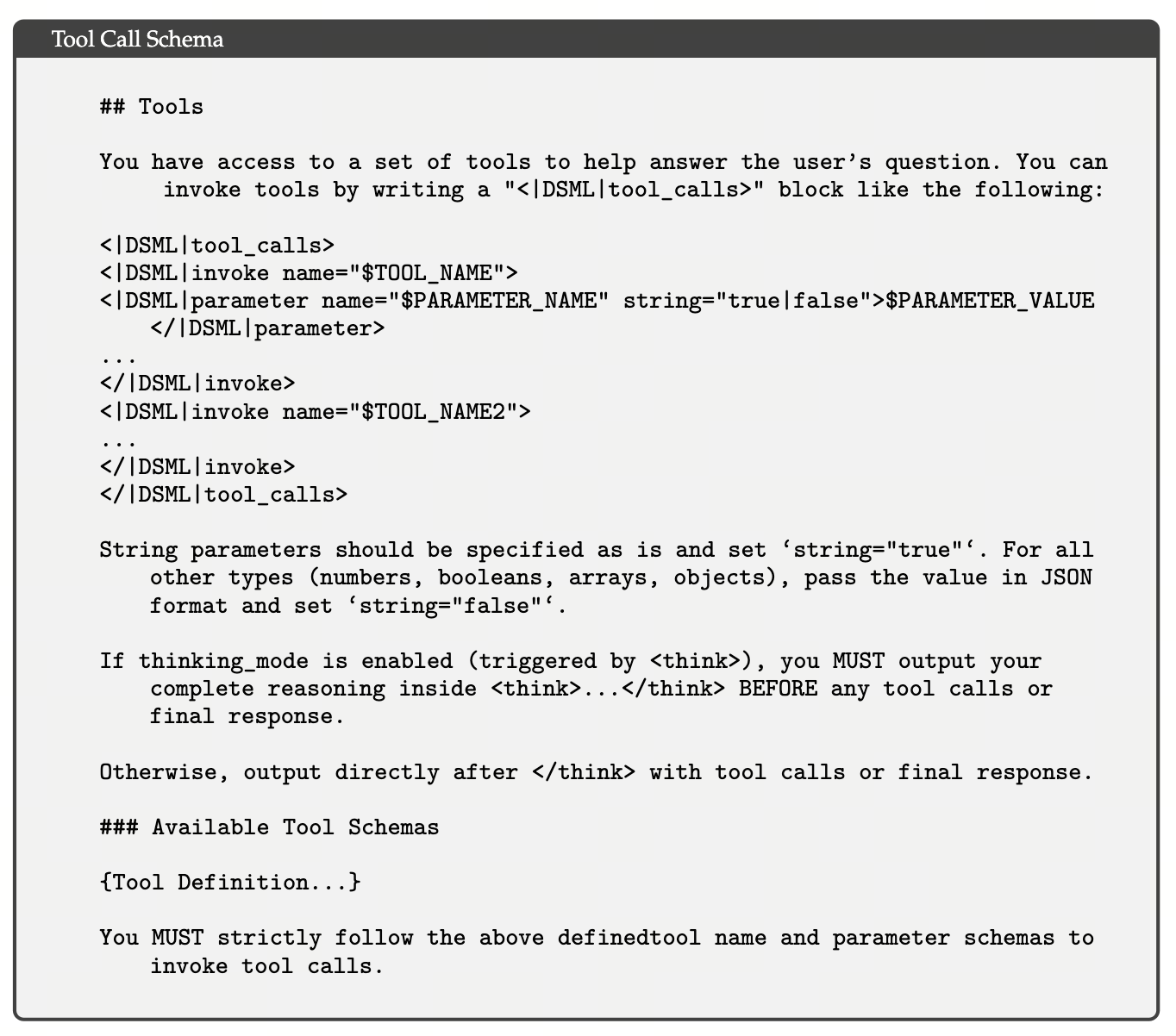
<|DSML|tool_calls>…</|DSML|tool_calls> 包住整段调用,每个调用用 <|DSML|invoke name="$TOOL_NAME"> 起手,参数走 <|DSML|parameter name="$PARAMETER_NAME" string="true|false">。string="true" 时值是字符串原样,string="false" 时值要在 JSON 里走格式(数值 / bool / 数组 / 对象)。最后一句 If thinking_mode is enabled (triggered by <think>), you MUST complete your reasoning including </think> BEFORE any tool calls or final response —— thinking 必须先收尾,再 tool call。整套 schema 用特殊 token 边界而非 JSON 分隔符,这就是 V4 比 OpenAI 的 JSON Function Calling 解析失败率低一个数量级的根因。
来源:DeepSeek-V4 技术报告 §5.1.1 Specialist Training(Tool-Call Schema),Table 4,p. 31。
2. Interleaved Thinking:让多轮 Agent 不丢解题状态
一个 Agent 调试场景:模型读了仓库 README → think 了一遍架构 → 调 grep → 看到结果 → think 一遍下一步 → 调 read_file……每轮 think 是基于之前所有信息的累积理解。
V3.2 的处理:新一轮 user 消息(或 tool result)到来时,旧 thinking 段整段从 context 删除。动机是控制 context 长度。代价:第 50 轮的 think 看不到第 1 轮"我之所以选这条调试路径是因为 ...",必须从头建立。长 horizon 任务的解题状态持续被重置。
- V3.2(丢弃 thinking):第 N 轮 input = 系统 prompt + 历史 (tool calls + results + answers) ≈ 系统 + N×(50+100) = 150N token;
- V4(保留 thinking):第 N 轮 input ≈ 系统 + N×(600+50+100) = 750N token;
- 50 轮:V3.2 = 7.5K token,V4 = 37.5K token。
| 场景 | thinking 处理 | 动机 |
|---|---|---|
| Tool-Calling Mode | 跨所有轮次完整保留所有 thinking trace,跨 user message 边界也保留 | long-horizon Agent 需要连贯解题状态 |
| 普通对话 | 新 user 消息时丢弃旧 thinking,仅保留 final answer | 避免日常对话被无关思考链拖累 |
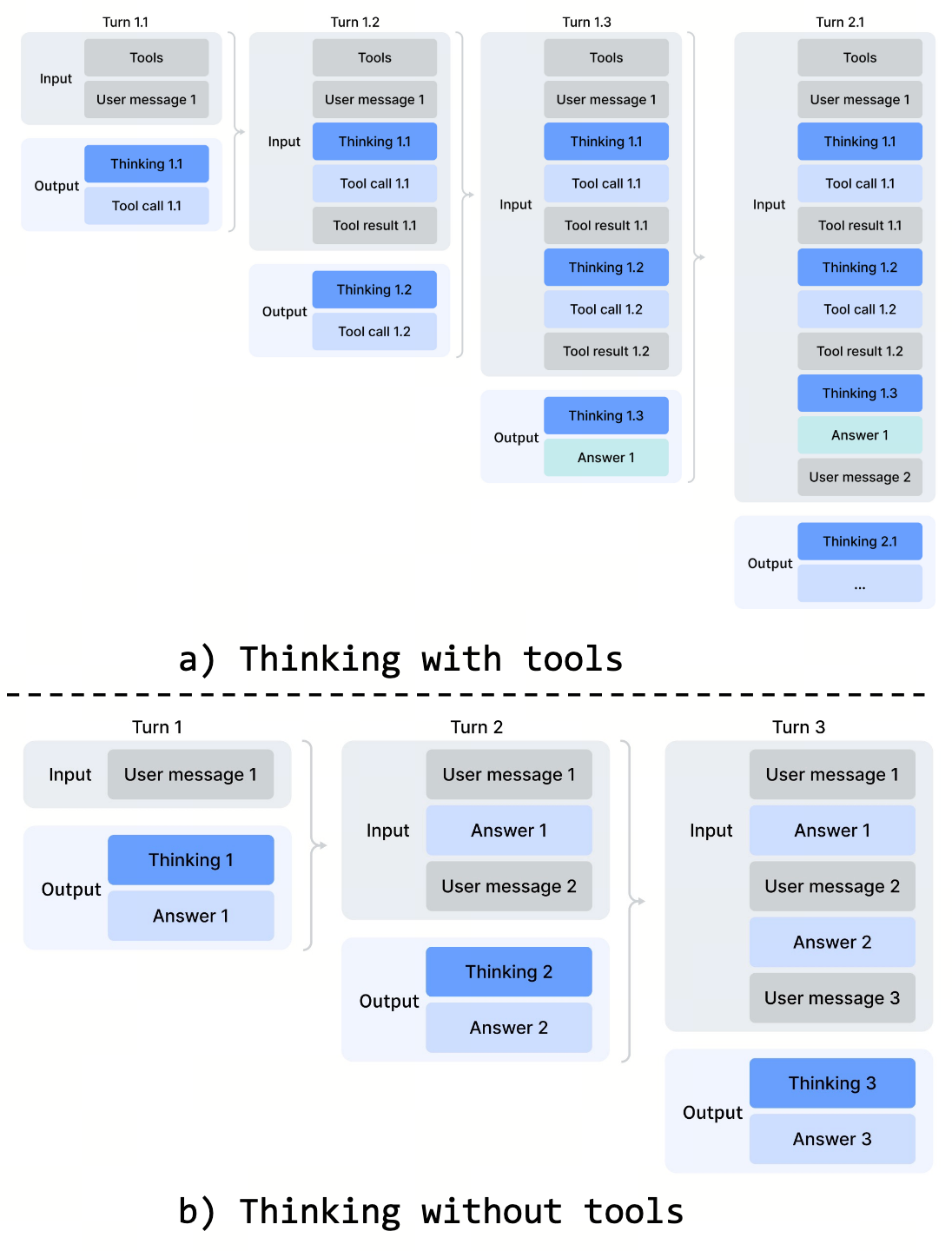
像 Terminus 这类把工具结果包装成 user message注入回模型的 Agent 框架,不会触发"保留 thinking"的代码路径 —— V4 区分 tool result 与 user message 是看 schema 而不是看角色字符串。论文建议这类架构使用 non-think 模型,或者改用 DSML schema 让 V4 识别真正的 tool-call。
3. Quick Instruction:把判定逻辑压进 token
Chatbot 实际 pipeline 在正式回答前要做一连串判定型任务:
- 这个 prompt 是否需要联网搜索?
- 如果搜索,query 应该改写成什么?
- 意图属于哪一类(编程 / 闲聊 / 知识问答 / ...)?
- 来源权威性要求高吗(医疗 / 法律)?
- prompt 里的 URL 要不要抓取?
- 这次会话起个什么标题?
传统做法:训 6 个独立小模型,每个模型独立 prefill 一遍 prompt 后输出判定。每个独立 prefill = 一次 O(n²) attention,6 个判定 = 6 次 prefill。TTFT 累积到秒级。
V4 的反传统做法:把每个判定编码成1 个特殊 token,附在主 prompt 尾部。论文 Table 中列出的 6 个 token 对应 6 个判定任务。
| Token | 作用 | 触发位置 |
|---|---|---|
<|action|> | 判定 user prompt 是否需要 web 搜索 | user → assistant 之间 |
<|title|> | 第一轮回答后生成会话标题 | assistant 完结后 |
<|query|> | 为 user prompt 生成搜索 query | user 后 |
<|authority|> | 判断 prompt 对源权威性的需求 | user 后 |
<|domain|> | 识别 user prompt 的领域 | user 后 |
<|extracted_url|> / <|read_url|> | 判断 URL 是否需要抓取 | 带 URL 的 prompt 后 |

...<|User|>{prompt}<think></think><|action|>,决定是否联网搜索;
<|title|> 形如 ...<|Assistant|>{response}<|end_of_sentence|><|title|>,第一轮回答后追加生成对话标题;
<|query|> 把 user prompt 改写成搜索 query;
<|authority|> 给 prompt 打"对来源权威性的需求"标;
<|domain|> 给 prompt 分领域;
<|extracted_url|> / <|read_url|> 决定每个 URL 是否要抓取并读取。
这些副任务不需要再叫一次模型—— 主 prompt 末尾追加对应特殊 token,复用已经算好的 KV,输出几十个 token 就完事。
来源:DeepSeek-V4 技术报告 §5.1.1 Specialist Training(Quick Instruction),Table 5,p. 33。
关键是 KV cache 共享。一次 prefill 后,主 prompt 的所有 token 的 K/V 都在 GPU 显存里。给同一 prompt 追加 1 个特殊 token:
- 主 prompt $n$ token 的 prefill 已经做过(用户主回答需要它,本来就要做);
- 追加
<|action|>这 1 个 token 后,attention 只需算这个 token 的 Q 与全部 K 的点积 —— $O(n)$,不是 $O(n^2)$; - 解码器输出"是否搜索"的判定 token(如 "yes" / "no")。
所以 6 个 Quick Instruction 任务 ≈ 6 次"1 token decode",总开销是一次 prefill 的零头。这是把"控制平面"嵌进"数据平面"换来的物理收益。
读图法:上排是传统方案 —— 6 个独立小模型每个都要 full prefill 一遍主 prompt(黄段),TTFT 随 prompt 长度线性堆 6 次。下排是 Quick Instruction —— 1 次主 prefill(蓝)+ 6 个 1-token decode(绿)。
把 prompt 拉到 16K 以上看上下两条对比 —— 上排的总耗时几乎全是 prefill,下排几乎全是单次主 prefill,"加速比"轻松到 5-6× —— 这就是把判定从独立模型变成 token带来的物理收益。
4. 三件套共享的工程哲学
DSML / Interleaved Thinking / Quick Instruction 看似各管一摊,但都是同一种姿态的具体实现:
- DSML:把"工具调用"从外部 JSON parser 内化成词表里的特殊 token;
- Interleaved Thinking:把"解题状态"从外部 state machine 内化成长 context 里的 token 序列;
- Quick Instruction:把"判定逻辑"从独立小模型内化成追加在主 prompt 尾部的特殊 token。
这三件事少了哪一件,agentic post-training 都跑不起来 —— 每多一个外部组件,就多一份运维成本、版本对齐成本、TTFT 成本、错误模式。把控制平面压进数据平面是 V4 在交互层与 Ch12 KV 异构、Ch6 Muon 删 QK-Clip 一脉相承的工程哲学。
5. 一句话总结
三件套都是"把控制平面压进数据平面"的具体实现 —— DSML 让工具调用没有解析失败、Interleaved Thinking 让多轮 Agent 不丢解题状态、Quick Instruction 让辅助任务共享主 KV。配合 Ch4-5 的 1M context 与 Ch12 的 KV 异构调度,V4 才真正能让 agentic 工作流跑得起、跑得顺。